
What I Think About When I Think About Coupling
October 28, 2020
The phrase “loosely coupled” is used alongside “microservices“ so often you'd be forgiven for assuming you get loose coupling for free, just by “doing“ microservices. (Spoiler: you don't.) But what actually is coupling? How loose is loose? Should we also be worried about cohesion? And why do we care?
Introduction
Talking about Coupling & Cohesion
Before we begin it needs acknowledging - talking about coupling and cohesion is hard! Informal conversations often rely on intuition and analogy, and while academic research has given us reams of classification schemes and complex formulas, they are infrequently applied in commercial development.
In my experience, part of the problem is that over the years the industry's understanding of coupling and cohesion has expanded dramatically, leading to a number of different ways of thinking about the concepts. While all of these ways are linked by a common thread, that commonality is not always apparent, and the reason why coupling is important can become disconnected from its definition. I've had conversations with other engineers where it felt like we were speaking completely different languages when trying to discuss the merits or risks of a particular design with respect to coupling.
When talking about loose coupling, we have the added challenge of relativity - loose is often not used as an absolute. Frequently it is used to talk implicitly about looser coupling, compared with what came before. A system might be described as loosely coupled - and it may well be, next to a previous iteration of the same system - yet it may still exhibit many characteristics of tight coupling.
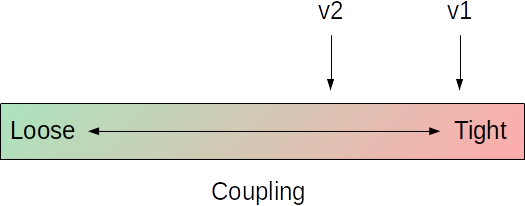
The aim of this blog post is to summarise a number of the most common ways of thinking about coupling and cohesion, and hopefully draw out the common thread that links them all.
Why do we care?
The concepts of coupling & cohesion are not new. They were developed by Larry Constantine in the late 1960s and 70s as part of a broader idea called "Structured Design".
In 1979, Constantine and Edward Yourdon published Structured Design: Fundamentals of a Discipline of Computer Program and System Design.

The book contained explorations of these relatively new ideas, with the inspiration noted as:
For a given problem, the human error production and, therefore, the cost of coding, debugging, maintenance, and modification are minimized when the problem is subdivided into the smallest functional units that can be treated independently
With a focus on the cost of a software project, Structured Design had the economics of software development firmly in mind.
So why do we care? The first reason, historically speaking, is that the concepts were invented specifically to help design software that is less costly to implement and maintain.
But how did they propose to achieve this goal? They started by investigating what seemed an unnecessary portion of the cost - dealing with errors (aka bugs, faults, defects). In particular, they honed in on the root cause of those errors - the humans who introduced them in the first place, and their capacity to deal with software's growing complexity.

As we work through this post, we are going to extend this map to illustrate how the different ways of thinking about coupling and cohesion relate to these goals.
Ways of Thinking about Coupling & Cohesion
The Basics
Before taking that thought further, it will help to establish some baseline understanding about the general structures involved.
Any system can be thought of as a collection of interconnected components (Constantine's "functional units"). In Structured Design, he referred to them as modules, but the principles apply to any type of component. In Object Oriented Programming, you might be talking about a class, or at a higher level you might consider a package, or assembly. In Microservices architectures, you're typically talking about an independently deployed and operating microservice.
With that in mind, we can start with some basics:
- Coupling is about the relationship between two components.
- Cohesion is about the internals of a component.
Since coupling is about relationships, it's important to note that it is directional. Components A & B are coupled if there is any kind of relationship between them but the impact of B on A might be far more significant than the impact of A on B.
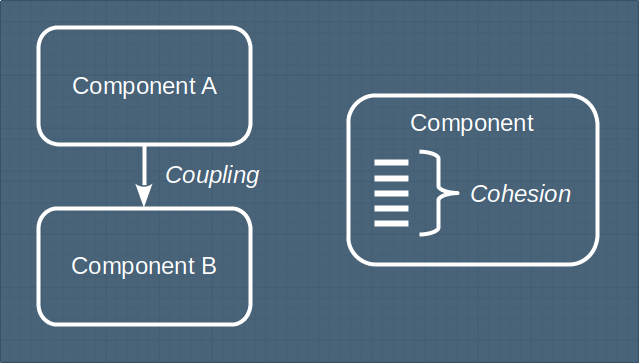
Coupling
We're going to talk about coupling first, and for the purposes of this post, I've loosely grouped the ways of thinking about it into three conceptual models:
Software is written by people
In pursuit of more cost effective software development practices, Constantine noted that most of the cost of system development is in fixing bugs - in other words, correcting errors made by humans. To reduce the cost, he went looking for ways to reduce the bug-rate.
It's been observed that humans have an information processing limit of about 7±2 objects at any point in time. Constantine concluded from this that most sources of human-introduced errors are a result of attempting to code modules that are naturally too complex for humans to understand.
In Constantine and Yourdon's own words:
The key question is: How much of one module must be known in order to understand another module? The more that we must know of module B in order to understand module A, the more closely connected A is to B. The fact that we must know something about another module is a priori evidence of some degree of interconnection even if the form of the interconnection is not known.
...
The measure that we are seeking is known as coupling; it is a measure of the strength of interconnection. ... Obviously, what we are striving for is loosely coupled systems --- that is, systems in which one can study (or debug, or maintain) any one module without having to know very much about any other modules in the system.
Coupling as an abstract concept --- the degree of interdependence between modules --- may be operationalized as the probability that in coding, debugging, or modifying one module, a programmer will have to take into account something about another module. [1]
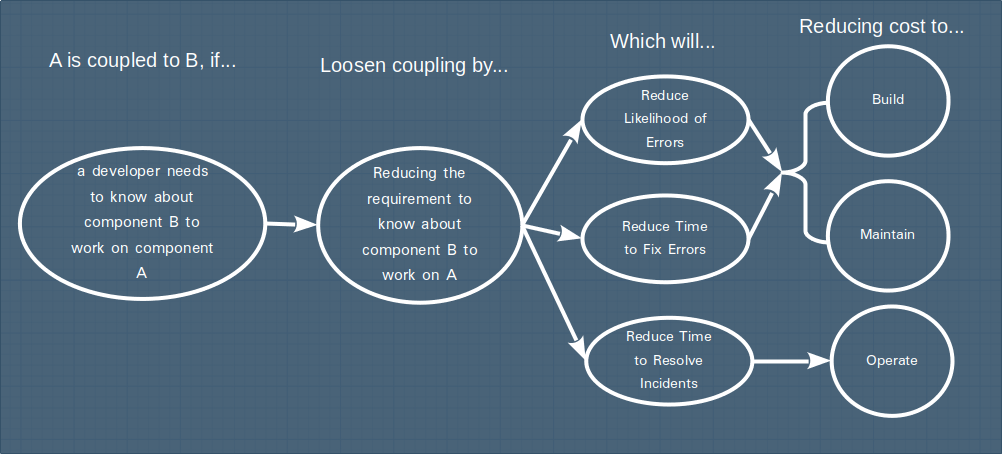
This definition clearly incorporates the limitations of human thinking - if a developer needs to keep facts about component B in their head while working on component A, then we increase the likelihood that we will exceed the 7±2 object limit - bugs will inevitably follow!

Following this to its logical conclusion, we can reduce coupling by arranging our system design such that in order to work on a given component, we do not need to know much about other components. This has a strong link to the idea of designing for high cohesion - further details below.
An interesting aspect of this way of thinking relates to modern DevOps style of working in that errors while developing are one thing but errors at run-time become operational incidents. For the same reason that looser coupling makes things easier when designing and bugfixing, it also makes operational incidents easier to resolve as the response team will have less parts of the system to think about and can focus on the component with the fault.
To visualise this way of thinking about coupling we can map out the chain of reasoning:
Interconnections Between Components
Constantine & Yourdan were quoted above: "The fact that we must know something about another module is a priori evidence of some degree of interconnection even if the form of the interconnection is not known."
In the search for ways of objectively measuring this degree of interconnection, researchers have necessarily needed to focus on scenarios where the form of the interconnection is known.
For example, an interconnection might be:
- A call to a method in another class
- A dependency on another package or assembly
- A remote API call
- A message exchange via a queue
The outcome of this research is probably given the most attention in the formal software engineering education and online documentation. For example, Wikipedia's article on Coupling and other online tutorials contain a laundry list of coupling types under various classification schemes as well as formula for computing a coupling metric based on these specific methods of interconnection.
These formula and classification schemes are thoroughly and expertly discussed elsewhere so I won't repeat them here, but I would like to discuss some of the extra benefits of loose coupling that have been identified through the research that produced them. These further benefits all contribute to reducing the cost to build, maintain and operate software systems.
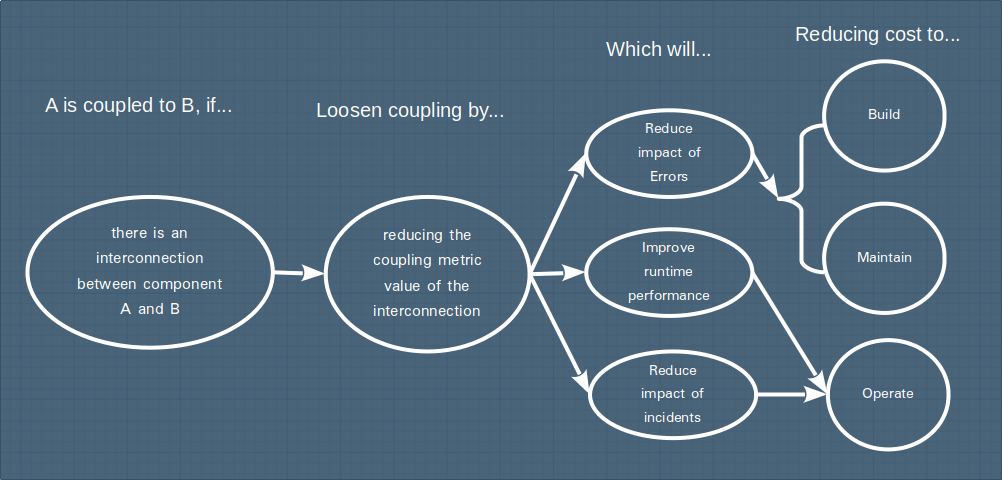
By reducing the degree of interconnection between components (i.e. looser coupling), we achieve the following benefits:
Reduce error impact
When there is an interconnection between components, a fault in one component can cause failures in other components. For example, if ClassA calls a method on ClassB then does something with the return value, a bug in ClassB can manifest as an incorrect result in ClassA. Hopefully you have unit testing to catch and isolate these sorts of errors, but reducing coupling will reduce their likelihood altogether.
Improve runtime performance
At runtime, inter-process interconnections (such as remote API calls between microservices) carry a performance overhead, and introduce temporal coupling - that is, the execution time of the caller is affected by the execution time of the callee. This latter point is part of why asynchronous message queues are often recommended for inter-process communications.
Reduce incident impact
An incident in a component can spread to other components. For example, when a component is experiencing an incident, it may become unavailable to components that connect to it, or present degraded service quality. In the reverse direction, a component experiencing an issue can overload components that it calls out to. Reducing coupling can help isolate the incident and reduce its spread, improving availability and reliability.
To visualise this way of thinking about coupling, once again we can map out the chain of reasoning:
Change Blast Radius
The observation that loose coupling reduces the impact of errors was first published in a book based on Constantine's work called The Practical Guide To Structured Systems Design by Meilir Page-Jones.
This way of thinking about the impact of the relationship between components has come to be known as the "blast radius" of the component. It's usually defined in terms of the number of other components affected by an event in the component. The looser (or fewer) the connections a component has with other components, then the blast radius of the event is smaller. (Note: Page-Jones did not use the term "blast radius" - this is a more modern term for the same concept.)
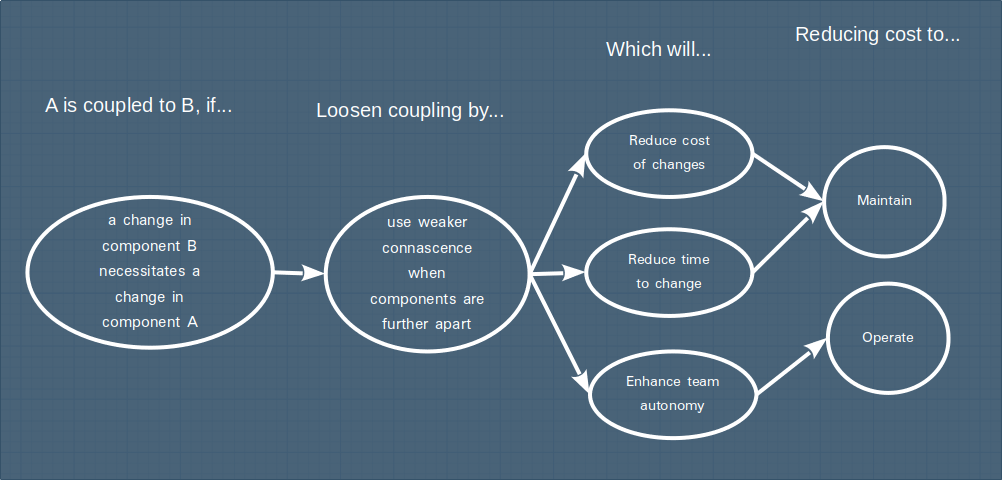
Errors & incidents are types of events that can have a blast radius. Another type of event is a change.
It is a rare software system that is built once and never modified. Software systems, especially in the modern product-led Saas world, are living things, undergoing continuous evolution. Inspiration for changes can come from anywhere - a startup pivot, a strategic review, customer feedback, operational efficiency goals, just to scratch the surface!
When embarking on a change, one has to start by considering the component(s) most obviously responsible for the functionality that needs to change - and then work out if any of the changes impact other components. Components that are tightly coupled are more likely to require changes to accommodate the initial change; conversely, components that are loosely coupled are less likely.
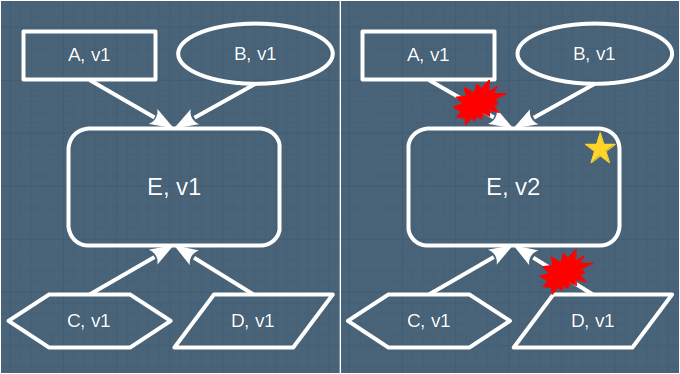
In the image above, when component E is updated to v2, components A and D are broken - they are in the blast radius of this change. To complete the change successfully, they must also be updated - adding cost and time to the change, especially if those components are owned by other teams.
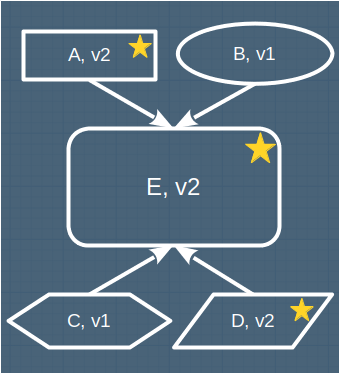
The analysis of change impact is so significant that Page-Jones continued his research in this area and ended up coining a new term just to describe it: Connascence. Connascence has also been analysed in formal research and https://connascence.io has a good summary of the classification schemes that have been produced.
This way of thinking about coupling has become one of the most popular informal understandings I've seen (although the term connascence appears less well known). In fact for many engineers, this has become the default, and most intuitive way of thinking about coupling. For example, this tweet from Kent Beck defines coupling exactly in this way:
I do think that this focus on the impact of change reveals one of the most challenging aspects of striving for loose coupling - in many scenarios, predicting the future types of changes is almost impossible, particularly when in response to a startup pivot, or a strategic review. We'll consider these types of changes more in a future post about the Logical View.
A formal concept associated with this idea of change is the Instability Index - a metric derived by analysing the number of "inbound" vs "outbound" dependencies, with the goal of predicting the "instability" of the component - or how likely it is going to need to change when other related components change.
Similarly to errors, there is a run-time impact of connascence, particularly in the world of microservices. One of the goals of microservices is to have independently deployable units, owned by autonomous teams. If two microservices have a high degree of connascence, then it's more likely that a change in one microservice will necessitate a change in another - reducing the likelihood that the change in the first service can be safely deployed without coordinating the deployment of the consequent change in the other service, and thus reducing team autonomy.
Once again, we can visualise this way of thinking by mapping out the chain of reasoning:
Cohesion
Cohesion naturally follows as a sort of inverse of coupling:
'Intramodular functional relatedness' is a clumsy term. What we are considering is the cohesion of each module in isolation --- how tightly bound or related its internal elements are to one another.
...
Clearly, cohesion and coupling are interrelated. The greater the cohesion of individual modules in the system, the lower the coupling between modules will be. ...
Both coupling and cohesion are powerful tools in the design of modular structures, but of the two, cohesion emerges from extensive practice as more important. [1]
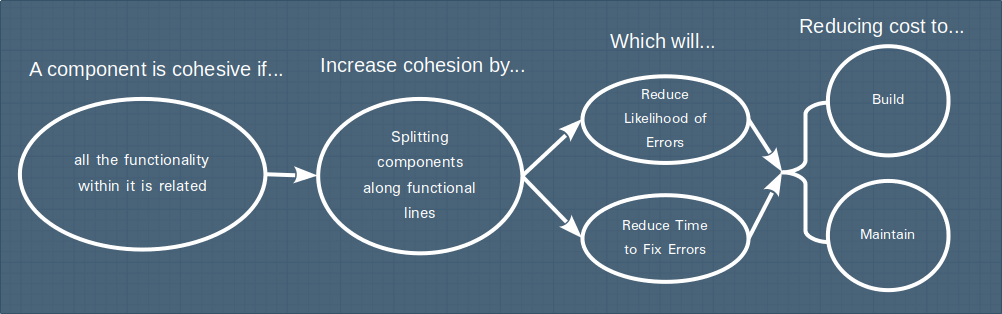
In other words, if all the functionality in a given component is related to the same idea then while the developer is working on that component there is less risk of other unrelated stuff taking up space in the 7±2 object limit and crowding out the relevant material.

It may come as a surprise that Constantine and Yourdan considered cohesion as more important than coupling, considering the industry focus on coupling, and the many ways it has come to be understood. I believe it makes some sense, though, given that they were focussed on the introduction of errors by humans. The other benefits of loose coupling had not yet been articulated.
While the word cohesive is less frequently used to describe microservices, this idea is at the heart of the advice to organise your services around "business capabilities" -- the intention is to ensure the functionality within each service is all related -- i.e. that the service is cohesive.
We can visualise the impact of cohesion similarly to coupling:
Conclusion
To bring together all our maps of the different ways of thinking about coupling and cohesion:
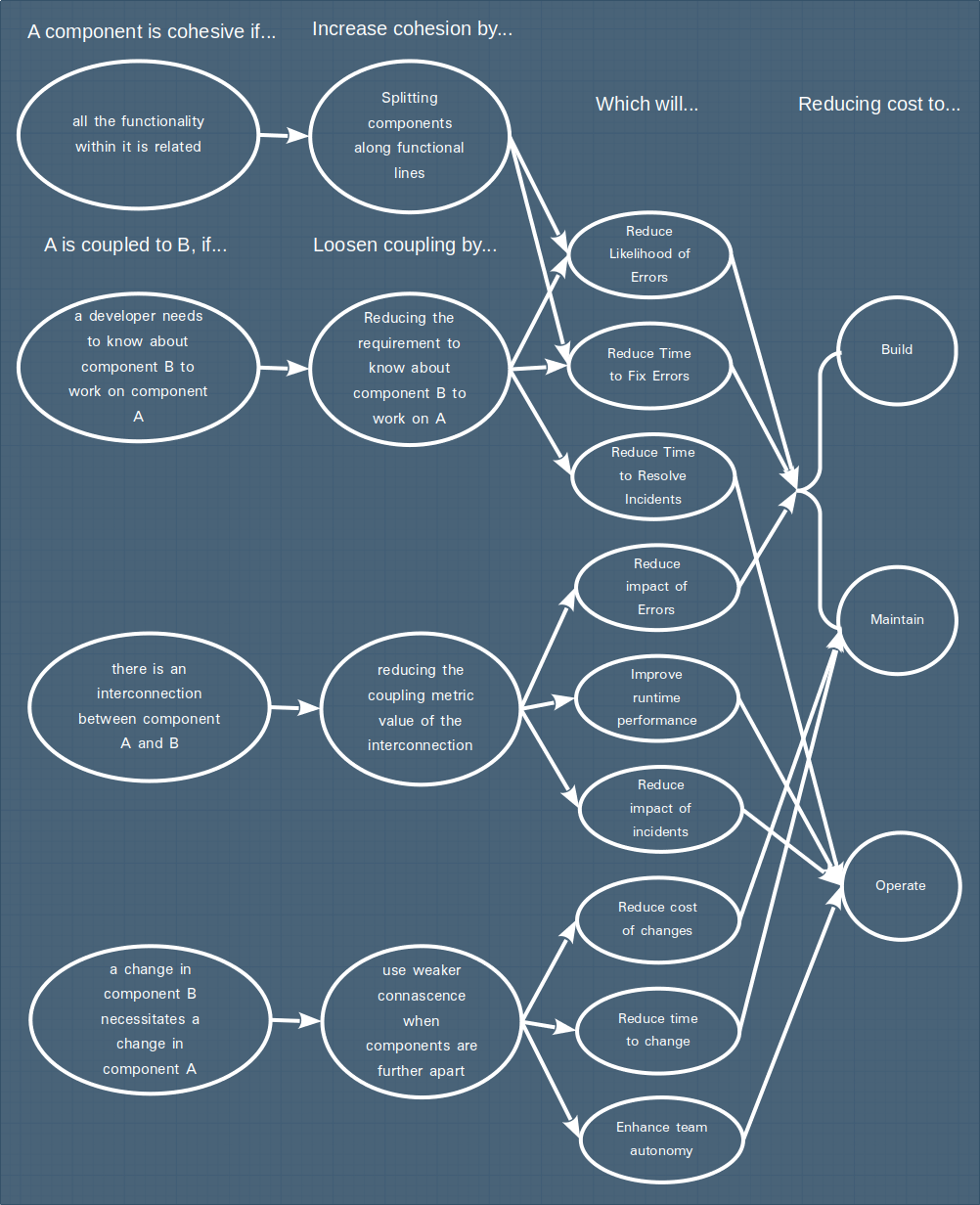
Given that most conversations focus on a narrow band of this landscape, it starts to make sense why these are such difficult topics to get your head around, particularly for people new to the field!
In summary, there are many different ways to think about coupling & in this post we've explored three:
- "Software is written by humans" - how much can we keep in our heads at one time
- "Interconnection between components" - the actual interconnections between components and their characteristics
- "Change blast radius" - changes, and the way they necessitate further changes in related components
In my experience, these different ways of thinking are at the root cause of many unfruitful conversations about coupling -- but while they appear different, hopefully it now makes sense that they are in fact all related. The common thread is the strength of relationships between components and the benefits of reducing the strength of those relationships. At different times and in different scenarios, you may find one way of thinking or the other more useful, and I encourage you to keep in mind the broader perspective so you can make an informed choice about when it makes sense to adopt a particular approach.
Stay tuned for future posts (coming soon!), in which we will apply these different ways of thinking to concrete code and system designs -- making good on the spoiler above to explain in detail why you don't get loose coupling for free just by "doing" microservices.
When returning to the series of posts about the 4+1 views, we will also analyse coupling & cohesion through the lens of each view, examining how different types of coupling are more relevant in different views, and how increasing cohesion in one view can actually decrease it in another.
